Ingest pipeline¶
The ingest pipeline is the central component of the data acquision part of the system. It is responsible for producing self-contained measurement sets with the visibility data and appropriate metadata. Under normal circumstances, the ingest pipeline is started by the Central Processor Manager. The latter also has the ability to abort ingest pipeline. However, under typical operation it does not “stop” the ingest pipeline, it stopes when the metadata flowing from the Telescope Operating System’s Executive component indicates an observation has concluded. The Executive assembles configuration file for the ingest pipeline based on the current observation and the Facility Configuration Manager hostiting the system configuration information which is not expected to change frequently from one observation to another. See the ingest paper for more information on the ingest pipeline and its architecture.
Execution¶
The ingest pipeline is a C++ application which can both with MPI and as a standalone program. Assuming the library path environment variable contains the required dependencies it can be started like so:
<MPI wrapper> cpingest -c cpingest.in -l cpingest.log_cfg
Command Line Parameters¶
The CP manager accepts the following command line parameters:
Long Form |
Short Form |
Required |
Description |
|---|---|---|---|
–standalone |
-s |
No |
Run in standalone/single-process mode (no MPI). In this mode, no MPI initialisation or finalisation is done. Therefore, one must not use any features which require MPI. |
–config |
-c |
Yes |
After this parameter the file containing the program configuration must be provided. |
–log-config |
-l |
No |
After this optional parameter a Log4cxx configuration file is specified. If this option is not set, a default logger is used. |
General overview¶
The ingest pipeline can be viewed as a collection of tasks executed on the data sequentially. The processing always starts at the Source task, which is responsible for receiving data and for apppropriate formatting and tagging. The presence of a source task in the task chain is the requirement. However, the rest of the task chain can in principle be empty (although in this case the ingest pipeline will not store or process the data, it will only ingest it). The data writing task is called MS Sink. There is no requirement that the sink task should be the last in the chain. In fact, any task (except the source task) can be executed more than once with the same or different parameters. For example, one could write a full resolution data to one measurement set, then average to a lower resolution and write the result to a different measurement set. We plan to use this feature eventually for the on-the-fly calibration.
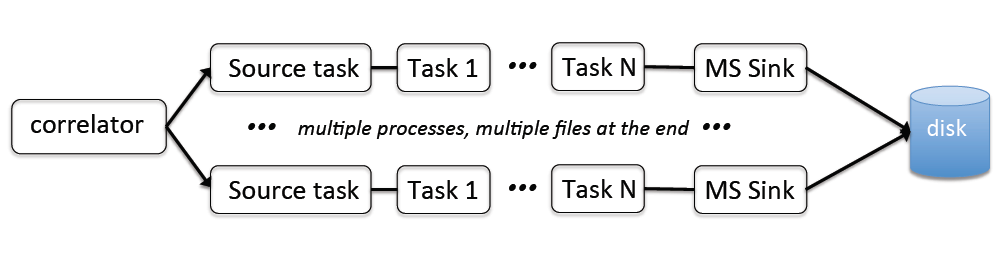
If used in the parallel (MPI) mode, the same task chain is replicated for each MPI rank to enable parallel processing. Source tasks are rank aware and increment accordingly the UDP port number which they listen to get the visiblity data. This allows us to have separate data streams processed by different ranks of ingest pipeline. By default, each rank does exactly the same operations according to the task chain but acts on a different portion of data. Therefore, the number of measurement sets written by the ingest pipeline is tied down to the number of ranks running the MS Sink task. The file name of the created measurement set can have a suffix added to distinguish between measurement sets written by different ranks. More than one file is usually required to increase the writing throughput. By default, all ranks always receive data (i.e. execute an appropriate Source task). However, later down the processing chain, each rank can be activated and deactivated by special type tasks which rearrange the data flow and parallelisation. If the given rank is not active, data are not passed through the task chain for this rank. This can be used to inhibit data writing for a subset of ranks. In particular, we use this feature of the task interface (see Merge task for details) to aggregade more bandwidth than is defined by the natural hardware-based distribution (one stream normally covers 4 MHz of bandwidth produced by a single correlator card). In the future, we envisage also to have tasks which would fork data streams to allow more parallel processing (e.g. a separate measurement set for calibration can be prepared in parallel). It is also possible to add so called service ranks (see below) which are not receiving any data. These ranks are deactivated by default and could be used for additional processing later on if some task activates them.
Configuration Parameters¶
The program requires a configuration file be provided on the command line. This section describes the valid parameters. In addition to mandatory parameters which are always required, individual tasks often have specific parameters which need to be defined only if a particular task is used.
General parameters¶
Parameter |
Type |
Default |
Description |
|---|---|---|---|
array.name |
string |
None |
Name of the telescope. It is only used to populate the appropriate field in the measurement set. But must be defined |
sbid |
uint |
0 |
Scheduling block number. This parameter is unused at the moment. |
tasks.tasklist |
vector<string> |
None |
List of tasks to be executed in the same order as they are given here. The first task listed is required to be a source task (e.g. MergedSource). Task names in this list can be chosen freely. The exact functionality is defined by the type keyword (see below). This is done to be able to reuse same tasks with different parameters throughout the task chain. See the example in the ChannelAvgTask description. We will refer to tasks by their type in this documentation, as they can be named arbitrarily in this list |
tasks.name.type |
string |
None |
Type of the task with the given name. The same operation can be performed more than once in the processing chain. For example, the same data can be written into multiple files with different spectral resolutions. To achieve this, the list of tasks contains names which are only references and can be named arbitrarily by the user. Actual physical operations are defined by the type keyword which is required for each name present in the task list. Each name can have separate parameters defined (see below). If each task is only used once, there is no reason why name and type could not be the same. |
tasks.name.params. |
varies |
varies |
This is the prefix to define task-specific parameters. Each task name listed in the tasklist parameter can have a separate set of paramters defined, even if there is more than one task of the same physical type. |
service_ranks |
vector<uint> |
[] |
If ingest has a rank listed in this parameter, it will be treated as a service rank, i.e. it will not receive data and will be de-activated at the start of the processing chain. All numbers in this list which exceed the total number of ranks available are ignored. |
hosts_map |
string |
None |
Strictly speaking, this is not the parameter of ingest itself, but rather the parameter consumed by the wrapper script which starts the proper MPI job. It controls the correct deployment of ingest pipeline with required number of ranks deployed on given nodes of the ingest cluster. The string is a comma-separated list of pairs of numbers separated, in turn, by semi-colons like “9:12,10:12,11:1”. The first number in each pair is the node number (i.e. 9 means galaxy-ingest09, 10 means galaxy-ingest10 and so on with leading zeros being added, if necessary), the second number represents the number of MPI ranks to be run on the given node. The ranks are assigned in the order of this list, i.e. the above mentioned example would result in MPI ranks 0 to 11 assigned to galaxy-ingest09, ranks 12 to 23 to galaxy-ingest10 and rank 24 would be assigned to galaxy-ingest11 by itself. The exact assignment is important for the following reasons: hardware sends data in a distributed way and each particular chunk of the frequency band is only available on a specific node, monitoring is configured in a certain way which may not be always convenient to change and, finally, service rank configuration is done by listing the rank numbers (see above). We typically would like to assign service ranks on those nodes which do not receive any data. The total number of ranks for the job is also deduced automatically. The map given as an example above would result in a 25-rank job. In principle, one can start ingest bypassing this script. |
Available tasks¶
Below is the list of tasks available. Note, although the intention is to document tasks which are intended as permanent, some temporary tasks are also documented. They can be taken out in the future.
Task |
Description |
|---|---|
Source task, merging visibility data streams and TOS metadata.This is the main source task intended for production operations. |
|
Source task faking metadata from parset. It is handy for some debugging |
|
Task to merge together parallel streams distributed in frequency |
|
CalcUVWTask |
Calculation of baseline projections (UVW). Temporary task, should be replaced by proper mechanism of distributing UVW with TOS metadata from the appropriate service. It doesn’t require any parameters. |
Sink task writing the measurement set. |
|
Sink task publishing visibilities to vispublisher. This allows to monitor data on the fly via vis and spd. Temporary task, we will not be able to use the same approach for full ASKAP, but keep it as long as we can as it is handy for debugging. |
|
An adapter task to run another task in parallel, in a service thread. Provided the child task execution time does not exceed the cycle time, this enables a better utilisation of available time as significant fraction of the cycle is spent gathering data which are sent asynchronously. Can be used with any task which does not alter data or distribution pattern. |
|
Task controlling on the fly fringe rotation in the ingest pipeline. A number of algorithms are available to apply the actual delay model, i.e. pure s/w-based, BETA specific DRx and hardware fringe rotator, ADE h/w fringe rotator, etc. This is a temporary task, as fringe rotation is expected to be done outside of SDP. |
|
Experimental task to detect and flag shadowed antennas on the fly. It supports basic interferometry mode and uses phase centre information to assess shadowing. Note, antennas excluded from data recording may also cause shadowing would not be detected. The task requires uvw information and, therefore, should be in the appropriate position in the task chain. |
|
CalTask |
Calibration task, part of implementation of predict forward approach. This task has never been tested or used, but some skeleton implementation exists. It will be worked on past early science. |
Task to average adjacent channels reducing the spectral resolution |
|
Task to split single data stream into a number of streams by beam |
|
Task to select a contiguous subset of spectral channels and discard the rest. This task is largely used for debugging and is not intended as permanent. |
|
DerippleTask |
BETA-specific task to remove the ripple caused by polyphase filters. It does not require any parameters, but needs the channel space to be aligned with coarse channels as it uses the absolute channel number to figure out of its place in the coarse channel. This task does not require any parameters. |
QuackTask |
Helper task to flag a number of cycles (two by default) following scan change. This is a task of temporary nature which shouldn’t be used long term. It gets just one optional parameter: ncycles, which is the number of cycles to flag (default is two) |
Basic on the fly flagging task. Currently, this task implements basic thresholding. The plan is to have special service delivering information about known RFI which has to be flagged. It is yet to be implemented and will be worked on past early science. On the fly flagging is essential for full ASKAP due to I/O limitations and data volume. |
|
ChannelFlagTask |
Early BETA task of temporary nature. It flags data based on static lists of channels supplied as ascii files per baseline. It was written to enable commissioning at the time significant memory errors were present. It shouldn’t be used in production system. |
PhaseTrackTask |
Early BETA task for unsynchronised phase tracking matching delay tracking done via the OSL script. The functionality is largely superseded by FringeRotationTask, but the code left in because parts of it are reused. Not to be used in production system. |
Beam arrangement (optional)¶
Parameters describing the beam arrangement are similar to the feeds configuration of csimulator. It is mainly used to initialise FEED table of the measurement set, but also used by calculation of the phase centres and projected baseline coordinates (uvw’s) if appropriate tasks are included in the chain. All beams are dual polarisation and linearly polarised (hard coded). Note, the term feed in the context of measurement sets really means beam. These parameters are optional, if ingest is configured to receive beam offsets information from the metadata (see MergedSource). However, they are required if configuration is such that static beam arrangements taken from parset is used (either a mode of MergedSource or a setup using NoMetadataSource; this is applicable only to functional tests now and should be irrelevant in normal operations).
Parameter |
Type |
Default |
Description |
|---|---|---|---|
feeds.n_feeds |
uint |
None |
Number of beams defined in the configuration. Note, only beams which are actually written to the measurement set need to be defined. |
feeds.feedN |
vector<double> |
None |
Dimensionless offset of the given beam from the boresight direction (given as [x,y]). Values are multiplied by feeds.spacing before being used. This also defined the units (assumed the same for all beams) to get a correct angular quantity.If feeds.spacing is not defined, the values in this parameter are treated as angular offsets in radians. The offsets should be defined for every N from 0 to feeds.n_feeds - 1 |
feeds.spacing |
quantity string |
None |
Optional parameter. If present, it determines the dimension and scaling of the beam layout (see above). If not defined, all beam offsets are assumed to be in radians. |
Antenna layout¶
Parameters describing antenna array configuration are similar to antennas section of csimulator configuration. It is used as a source of data to initialise ANTENNA table of the measurement set, but also used by calculation of the projected baseline coordinates (uvw’s) if appropriate tasks are included in the chain. Only antennas referred to from the baselinemap end up listed in the ANTENNA table (and therefore get an index in the measurement set), other antennas are simply ignored (as they don’t participate in the particular measurement and don’t contribute to the data written or processed past the source task). This section of the configuration is a slice of the antenna information stored by Facility Configuration Manager (FCM) and often contains parameters which are ignored by the ingest pipeline (e.g. the aboriginal name or pointing parameters) in addition to antennas unused in the particular experiment.
Parameter |
Type |
Default |
Description |
|---|---|---|---|
antennas |
vector<string> |
None |
List of antennas for which this section defines information. Names given here are just logical references used only in the names of appropriate configuration parameters. See baselinemap for the list of the actually used antennas. |
antenna.ant.diameter |
quantity string |
None |
Default diameter of antennas, used unless a specific value is defined explicitly for a given antenna. |
antenna.ant.mount |
string |
None |
Default mount of antennas, used unless the mount parameter is defined for a given antenna. Supported values are ‘equatorial’ ,’altaz’ and ‘askap’. The latter allows initialisation of the ANTENNA dynamically, depending on the 3rd axis mode shown by metadata. It is effectively equivalent to ‘equatorial’ for pa_fixed scan and to ‘altaz’ for pol_fixed. Mixing scans with different 3rd axis mode is not supported as it can confuse general purpose packages like casa which can be used in the short to medium term and for debugging. Note, NoMetadataSource task does not have access to metadata and pretends observations are done in the pa_fixed mode. Therefore, specifying ‘askap’ mount in the configuration in this case is equivalent to ‘equatorial’. Use explicit ‘altaz’ mount override, if necessary. |
antenna.ant.paf_rotation |
quantity string |
“0deg” |
Default PAF rotation angle. This angle is equivalent to the X feed rotation angle in the MS if the 3rd axis angle is zero (the 3rd axis setting is subtracted from it). |
the following parameters all have antenna.name prefix where name is an item in of the antennas list. Note, each element of this list should have all compulsory parameters defined. |
|||
<prefix>.name |
string |
None |
Name of the given antenna to be written into ANTENNA subtable, use this name in baselinemap.antennaidx to tie physical antenna with logical index used by the hardware. The names given in the antennas keyword are only used to form the prefix. |
<prefix>.location.itrf |
vector<double> |
None |
Vector with antenna coordinates in the ITRF frame in metres, i.e. X, Y, Z geocentric coordinates. |
<prefix>.diameter |
quantity string |
see above |
Optional parameter for diameter of the particular antenna. If not defined, the default value defined by the antenna.ant.diameter parameter (see above) will be used. |
<prefix>.mount |
string |
see above |
Optional mount type for the particular antenna. If not defined, the default value defined by the antenna.ant.mount parameter (see above) will be used. |
<prefix>.delay |
quantity string |
“0s” |
Optional fixed delay for the given antenna. It is used to compensate cable delays, delay jumps due to samplers, etc. Only required by fringe rotation tasks. This is a replacement for ingest-specific fixeddelay keyword used in earlier versions. The value is a quantity string. Units should be convertible to seconds. |
<prefix>.paf_rotation |
quantity string |
see above |
Optional PAF rotation angle for the given antenna. It is used instead of the default angle, if defined. See the antenna.ant.paf_rotation parameter above for more info. |
Baseline map¶
This section of parameters describes mapping between the output of the correlator and physical correlations stored in the measurement set. Technically, it should’ve been called correlation product map as it maps not only baselines but different polarisation products and even cross-pol products of auto-correlations.
Parameter |
Type |
Default |
Description |
|---|---|---|---|
baselinemap.antennaidx |
vector<string> |
None |
Correspondence between antenna names and antenna indices in the measurement set (assumed also to be equal to the indices implied by the hardware unless baseline.antennaindices keyword is given). Indices are assigned in the order antenna names are given in this list starting from zero. Note, check the section on the antenna layout for futher information on how the antenna names are defined. All antennas listed here should be defined in that section. Defined antennas which are not listed here are ignored by the ingest pipeline. |
baselinemap.antennaindices |
vector<int> |
None |
Optional parameter which allows a sparse map of hardware indices. This is helpful as antennas become available in a non-sequential order and we don’t want to waste disk space by for example always writing flagged data for ak01 antenna despite not having it in the array, or reconfigure/repatch the hardware every time we have a new antenna added. However, this slicing of the baseline map relies on implementation which is fundamentally inefficient. At this stage, it wasn’t found to be a bottle neck, but we may have to remove this in the future if we encounter performance problems when we grow the array size. If this keyword is not defined, antenna indices as assumed by the correlator are defined in the natural order starting with zero for each antenna listed in baselinemap.antennaidx. If this parameter is defined, then each element of the vector gives the corresponding hardware index for each antenna in the baselinemap.antennaidx. The empty vector is the special case meaning to determine indices automatically from the names listed in baselinemap.antennaidx (for ADE, antenna names correspond to indices plus one). The names supported should be in the form of two letters followed by two numbers with zero padding if antenna number is below 10. Unless this special case is used, the number of elements in baselinemap.antennaidx and baselinemap.antennaindices should be the same. Note, there is an additional requirement that the resulting slice of the map should remain a lower or upper baseline triangle as in the original map. Listing antennas in the increasing order of their hardware indices is the way to ensure it (i.e. 6,1,3,15,8,9 for BETA and the natural antenna order for ADE). |
baselinemap.baselineids |
vector<int> |
None |
List of the correlation product indices to be mapped. This way to define the mapping is incompatible with the default map which can be set up via baselinemap.name, only one method should be used. This list should contain all product indices understood by the ingest pipeline. It will ignore any data sent by the hardware which correspond to an unsupported correlation product. All product index listed in here should be described via ‘baselinemap.N‘ parameter which must be defined (N is the index). |
baselinemap.N |
[int,int,string] |
None |
Description of the correlation product N. This parameter should be present for all product indices listed in the baselinemap.baselineids parameter. If the latter is not defined (i.e. the pre-defined map is used), this parameer will be ignored. The value should be a 3-element tuple with antenna indices (matching baselinemap.antennaidx) for the first and the second antenna of the given baseline, and the polarisation product. For example, [0,1,XX] defines baseline between the first and the second antennas (note, indices are the same as in the measurement set and, therefore, 0-based) and XX polarisation, i.e. parallel-hand X polarisation. It is assumed that the signal from the second antenna is conjugated. The map itself supports arbitrary and even sparse mapping, but other parts of ingest pipeline require either upper or lower baseline triangle for performance reasons. |
baselinemap.name |
string |
None |
An alternative way to specify baseline map using a pre-defined algorithmic description. The only currently supported setting is ‘standard‘ which produces the map for the ASKAP correlator (as of December 2015). This correlator produces 2628 different products which description would bloat the configuration file otherwise. This option is incompatible with the baselinemap.baselineids keyword. |
baselinemap.standard.nant |
unsigned int |
36 |
Number of antennas passed to the default product generator for the ASKAP correlator. Note, the products come in a very mixed up order. If we ever get the correlator to support a different number of antennas, this format would probably change anyway. This parameter is only used if the ‘standard‘ mapping is chosen. |
baselinemap.standard.swappols |
boolean |
false |
If true, X will be replaced by Y and vice versa in the algorithmic model. This parameter is only used if the ‘standard‘ mapping is chosen. |
Correlator modes¶
This section describes the data expected from the correlator. It is largely inherited from BETA and some future changes are expected in this area to support different frequency tunings of ASKAP. For the parallel environment, the description applies to single card only. Different configurations of the input data could change in run time, but all possible configurations should be defined up front (so the appropriate SPECTRAL_WINDOW table can be created).
Parameter |
Type |
Default |
Description |
|---|---|---|---|
correlator.modes |
vector<string> |
None |
List of supported modes. An exception will be raised if received metadata request a correlator mode which has not been defined in the configuration file. Each mode listed here should have the following parameters defined. Modes not listed are ignored, even if their parameters are defined. Also note, that the mode named standard acts as default for most of the parameters of all other modes (i.e. the user can define correlator interval only for the standard mode and it will be used for all other modes, unless redefined). However, there is no requirement to have standard mode defined. |
All following parameters have correlator.mode.name prefix, where name is a mode listed in correlator.modes |
|||
<prefix>.chan_width |
quantity string |
taken from standard mode |
Separation of the channels in frequency, which is always assumed to be equal to the channel width. Full quantity string with sign (for inverted spectra) and units. |
<prefix>.interval |
uint |
taken from standard mode |
Correlator cycle time in microseconds. |
<prefix>.n_chan |
uint |
taken from standard mode |
Number of spectral channels handled by a single source task. In parallel environment, this is the number of channels in the single data stream (normally - single card). |
<prefix>.stokes |
vector<string> |
taken from standard mode |
List of products in the polarisation vector in the order as they are to be stored in the measurement set. Although, in principle, all polarisation frames, including incomplete and mixed frames, are supported here and in the definition of correlation products, other frames than full linear are likely to cause problems elsewhere. |
<prefix>.freq_offset |
quantity string |
“0Hz” |
Ingest pipeline constructs frequency axis up front as data not always arrive, but we want a contiguous structure with regular increments. Each receiving rank is setup independently assuming the band is contiguous. The central frequency has therefore different meaning depending on how many ranks are in the job and what part of the band is received by ingest. This parameter encapsulates all the complexity. It is the frequency offset to get the centre of the band processed by the first card. The numbers change depending on the zoom mode. |
Monitoring via Ice¶
A number of tasks and the ingest pipeline itself are able to publish monitoring information via Ice. Parameters in this section control the details. Some parameters support substitution rules which could evaluate differently at different ranks. The same code is used here as for the filename parameter of the MSSink task (so more fine tuning options are either available or could easily be made available), but in general, only %r evaluating to the rank number is typically of interest here. Note, if the job has multiple ranks and the monitoring is enabled, the application ensures that at least one of the parameters which could be rank-dependent (see the table below) evaluate to different value on different ranks (an exception is raised otherwise).
Parameter |
Type |
Default |
Description |
|---|---|---|---|
monitoring.enabled |
boolean |
false |
If true, then monitoring information is published via Ice. Otherwise, the code does not attempt to talk to Ice at all. |
monitoring.servicename |
string |
None |
If monitoring is enabled, this parameter must be specified. This parameter provides the name of the monitoring service interface that will be registered in the Ice locator service. An example would be “MonitoringService”. This parameter supports substitution rules (i.e. %r will be replaced by the rank number) although we don’t setup it this way operationally at the moment using adaptername and prefix to discriminate between monitoring data produced by different ranks. |
monitoring.adaptername |
string |
None |
If monitoring is enabled, this parameter must be specified. This parameter provides the name of the adapter on which the monitoring service proxy object will be hosted. This parameter supports substitution rules (i.e. %r will be replaced by the rank number). |
monitoring.prefix |
string |
None |
If monitoring is enabled, this parameter must be specified. It will be prepended to the names of all monitoring points when the monitoring information is published. Together with the adapter name, we use this prefix to distinguish between monitoring data sent by different ranks. This parameter supports substitution rules (i.e. %r will be replaced by the rank number). |
monitoring.ice.locator_host |
string |
None |
If monitoring is enabled, this parameter must be specified. Host name for the Ice locator service. |
monitoring.ice.locator_port |
string |
None |
If monitoring is enabled, this parameter must be specified. Port number for the Ice locator service. |
Metadata access via Ice¶
The metadata are distributed by the Telescope Operating System (TOS) via Ice. This section contains Ice-related parameters to set up metadata source (subscriber to Ice messages). These parameters are not required if NoMetadataSource is used as the Source task.
Parameter |
Type |
Default |
Description |
|---|---|---|---|
metadata_source.ice.locator_host |
string |
None |
Host name for the Ice locator service |
metadata_source.ice.locator_port |
string |
None |
Port number for the Ice locator service |
metadata_source.icestorm.topicmanager |
string |
None |
Topic manager string, e.g. IceStorm/TopicManager@IceStorm.TopicManager |
metadata.topic |
string |
None |
The name of the Ice topic used to distribute metadata |
Example¶
########################## Array configuration #########################
# Antennas
antenna.ant.diameter = 12m
antenna.ant.mount = equatorial
antenna.ant12.location.itrf = [-2556496.23395074, 5097333.71443976, -2848187.33832738]
antenna.ant12.name = ak12
antenna.ant12.delay = -1016.9128ns
antenna.ant13.location.itrf = [-2556407.33285999, 5097064.98559973, -2848756.02202956]
antenna.ant13.name = ak13
antenna.ant13.delay = -1078.21449ns
antenna.ant14.location.itrf = [-2555972.78569203, 5097233.67554548, -2848839.90236005]
antenna.ant14.name = ak14
antenna.ant14.delay = 2761.49796ns
antenna.ant2.location.itrf = [-2556109.976515, 5097388.699862, -2848440.12097248]
antenna.ant2.name = ak02
antenna.ant2.delay = -197.211974ns
antenna.ant4.location.itrf = [-2556087.396082, 5097423.589662, -2848396.867933]
antenna.ant4.name = ak04
antenna.ant4.delay = 1.50248671ns
antenna.ant5.location.itrf = [-2556028.60799091, 5097451.46862483, -2848399.83113161]
antenna.ant5.name = ak05
antenna.ant5.delay = 275.712668ns
antennas = [ant2,ant4,ant5,ant12,ant13,ant14]
array.name = ASKAP
sbid = 335
# Correlation product map
baselinemap.antennaidx = [ak02, ak04, ak05, ak12, ak13, ak14]
baselinemap.antennaindices = [1, 3, 4, 11, 12, 13]
baselinemap.name = standard
# Correlator mode
correlator.mode.standard.chan_width = 18.518518kHz
correlator.mode.standard.interval = 5000000
correlator.mode.standard.n_chan = 216
correlator.mode.standard.stokes = [XX, XY, YX, YY]
correlator.modes = [standard]
# Beam configuration
feeds.n_feeds = 36
feeds.names = [PAF36]
feeds.spacing = 1deg
feeds.feed0 = [0., 0.]
feeds.feed1 = [0., 0.]
feeds.feed10 = [0., 0.]
feeds.feed11 = [0., 0.]
feeds.feed12 = [0., 0.]
feeds.feed13 = [0., 0.]
feeds.feed14 = [0., 0.]
feeds.feed15 = [0., 0.]
feeds.feed16 = [0., 0.]
feeds.feed17 = [0., 0.]
feeds.feed18 = [0., 0.]
feeds.feed19 = [0., 0.]
feeds.feed2 = [0., 0.]
feeds.feed20 = [0., 0.]
feeds.feed21 = [0., 0.]
feeds.feed22 = [0., 0.]
feeds.feed23 = [0., 0.]
feeds.feed24 = [0., 0.]
feeds.feed25 = [0., 0.]
feeds.feed26 = [0., 0.]
feeds.feed27 = [0., 0.]
feeds.feed28 = [0., 0.]
feeds.feed29 = [0., 0.]
feeds.feed3 = [0., 0.]
feeds.feed30 = [0., 0.]
feeds.feed31 = [0., 0.]
feeds.feed32 = [0., 0.]
feeds.feed33 = [0., 0.]
feeds.feed34 = [0., 0.]
feeds.feed35 = [0., 0.]
feeds.feed4 = [0., 0.]
feeds.feed5 = [0., 0.]
feeds.feed6 = [0., 0.]
feeds.feed7 = [0., 0.]
feeds.feed8 = [0., 0.]
feeds.feed9 = [0., 0.]
########################## Ice Properties ##############################
# TOS metadata
metadata.topic = metadata
metadata_source.ice.locator_host = aktos10
metadata_source.ice.locator_port = 4061
metadata_source.icestorm.topicmanager = IceStorm/TopicManager@IceStorm.TopicManager
# monitoring
monitoring.adaptername = IngestPipelineMonitoringAdapter%r
monitoring.enabled = true
monitoring.ice.locator_host = aktos10
monitoring.ice.locator_port = 4061
monitoring.prefix = ingest%r.cp.ingest.
monitoring.servicename = MonitoringService
########################## Tasks ##############################
tasks.tasklist = [MergedSource, Merge, CalcUVWTask, FringeRotationTask, MSSink, TCPSink]
# uvw calculation task; no parameters required
tasks.CalcUVWTask.type = CalcUVWTask
# s/w-based fringe rotation
tasks.FringeRotationTask.params.fixeddelays = [-198.004385, 0, 275.287053, -1018.02295, -1077.35682, 2759.82581]
tasks.FringeRotationTask.params.method = swdelays
tasks.FringeRotationTask.params.refant = AK04
tasks.FringeRotationTask.type = FringeRotationTask
# sink task writing the measurement set
tasks.MSSink.params.filename = %d_%t.ms
tasks.MSSink.params.pointingtable.enable = true
tasks.MSSink.params.stman.bucketsize = 131072
tasks.MSSink.params.stman.tilenchan = 216
tasks.MSSink.params.stman.tilencorr = 4
tasks.MSSink.type = MSSink
# merging of parallel streams
tasks.Merge.params.ranks2merge = 12
tasks.Merge.type = ChannelMergeTask
# visibility source joining visibilities and metadata
tasks.MergedSource.params.maxbeams = 36
tasks.MergedSource.params.n_channels.0 = 216
tasks.MergedSource.params.n_channels.1 = 216
tasks.MergedSource.params.n_channels.10 = 216
tasks.MergedSource.params.n_channels.11 = 216
tasks.MergedSource.params.n_channels.2 = 216
tasks.MergedSource.params.n_channels.3 = 216
tasks.MergedSource.params.n_channels.4 = 216
tasks.MergedSource.params.n_channels.5 = 216
tasks.MergedSource.params.n_channels.6 = 216
tasks.MergedSource.params.n_channels.7 = 216
tasks.MergedSource.params.n_channels.8 = 216
tasks.MergedSource.params.n_channels.9 = 216
tasks.MergedSource.params.vis_source.max_beamid = 36
tasks.MergedSource.params.vis_source.max_slice = 0
tasks.MergedSource.params.vis_source.port = 16384
tasks.MergedSource.params.vis_source.receive_buffer_size = 67108864
tasks.MergedSource.type = MergedSource
# sink task sending the data for monitoring via vis and spd
tasks.TCPSink.params.dest.hostname = aktos11.atnf.csiro.au
tasks.TCPSink.params.dest.port = 9001
tasks.TCPSink.type = TCPSink