




Next: AVAILABLE TASKS in AIPS
Up: SELF CALIBRATION
Previous: General
This section is only relevant for self calibration of images that have
not been made with multi-frequency synthesis techniques. That is,
you have just one channel (usually channel 0) that you are imaging and
self calibrating, not a band of channels. For self calibration of
multi-frequency synthesis images, you should use MIRIAD.
The task you will need for self-calibration is CALIB. Once again,
I have provided some procedures to help you do self-calibration with
a reduced set of CALIB's inputs. There is one procedure
for multi-source files called ATMCAL, and one for single-source files
called ATSCAL. If these are insufficient for your purposes, you
know what to do.
When you self-calibrate with a multi-source file, all you do is produce
a new CL table for application to the data; first you run CALIB to
generate the solutions, and then you interpolate them to a CL table
with CLCAL in the usual way. This means that the fundamental time
scale on which you can alter the gains is the CL table entry interval.
ATLOD builds the CL table with 3-minute intervals. You may have
something different if you have rebuilt it with INDXR (it defaults to
5-minute intervals).
On the other hand, with single-source files, each application of CALIB\
produces a new and corrected data base. This has the advantage that,
because there are no CL tables with single-source files, the fundamental
time scale on which you can correct the gains is the integration time of
the data (usually 10 seconds). The disadvantage is that you must
duplicate the data with each pass. If you are working on a large data
set, this may cause difficulty according to the available disk space.
- Let us continue now with a discussion of some of the adverbs for
multi-source self-calibration with ATMCAL. Many of the adverbs
have already been discussed in § 8, so I will
not cover them all.
- Select the source to self-calibrate with calsour and
calcode.
- Select the desired frequency with freqid.
- Calibrate the data by setting docalib=1 and by selecting
the correct CL table with gainuse. This will probably be version
2 if this is the first self-calibration pass following basic
calibration. If this is a later pass, then gainuse will be a
higher version number.
- Select the model, a list of CLEAN components, by filling in the
CLEANed image name with in2name, in2class, in2seq and
in2disk (use 2name). The version number of the CLEAN
component file is selected with invers (generally there is only
one CC table, so leave this at 0).
- ncomp selects the number of CLEAN components in the
CC table to use as the model, starting at one; this is a very important
parameter. Your goal is to provide CALIB with the best possible
model of the source, so you should not include CLEAN components
that are obviously wrong. One obvious example of this is a negative
component, as the source must be positive. A common technique is
to use all the components up to the first negative. However,
if you have just one bad component in a much more extensive list
of positive components, then it may prove advantageous to include
more components than this simple approach suggests.
This makes it clear why good windowing is so important during the CLEAN
step; it helps exclude the possibility of including wrong
components in the CLEAN model.
- uvrange is also a fairly important parameter. Your model
must match the data. Thus, as is often the case, if your model only
represents a source with high spatial frequencies and your data
contain a more extensive range of spatial frequencies, you must
exclude the data that are not represented in the model. Two numbers
are required, a minimum and maximum uv-distance, in
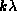 .
See also the task KALIB discussed at the end of this section.
.
See also the task KALIB discussed at the end of this section.
One good way to set this range is to make a plot of visibility amplitude
versus uv-distance with UVPLT. Find the total CLEANed flux density
in your model by listing the CLEAN component table, and look up
the corresponding uv-distance on the plot. Set the uvrange to
exclude the baselines interior to this value.
With VLA data, this is a fairly safe recipe, because there will be many
baselines in the selected uv range. However, with ATCA data, you must
be careful not to exclude too many baselines, such that a good solution
cannot be found. You must compromise between matching the data to the
model and and having as high a level of over-determination in the
problem as possible.
- It may be that your source is a point source, or that by suitably
restricting the uvrange, can be viewed as a point source (make
sure you still include enough baselines to get a decent solution). In this
case, rather than using a list of CLEAN components, you can specify a
point-source model with the smodel array. smodel(1) is the
flux density of the point source, smodel(2) is the x offset of
the point source from the phase centre in arcseconds, and
smodel(3) is the y offset. Note that if you leave the offsets at
zero, the self-calibration procedure has the freedom to phase-shift the
data so that the source appears at the phase centre (this can be a
useful way to move a point source to the centre of a grid cell).
Absolute position information is lost with self-calibration.
smodel can also be used for elliptical Gaussian models. See
HELP smodel for more information.
- solint controls the solution integration time (in minutes)
over which the gain changes are assumed to be constant. If you have
sufficient signal-to-noise ratios, integration times of the order of one
minute are a good starting place. Depending on the phase stability of
the data, this number may need to be shorter or longer. You will
probably need to experiment, but remember, for weak sources you should
make sure you set this long enough to ensure a signal-to-noise ratio of
at least a few on all baselines. However, this may preclude any useful
modification of the gains, if it is too long.
- The conventional wisdom at the VLA has always been that you should
first do a couple or a few phase-only self-calibration passes (
solmode='p') and then, once the phases are in order, attempt an
amplitude and phase self-calibration (solmode='a&p'). In my
experience with ATCA data, it is sometimes better to try and do phase
and amplitude straight away. I believe the reason is, that once errors
in the model get frozen in, they are particularly hard to remove with
ATCA data owing to the small number of baselines. Thus, you are better
off trying to remove both the amplitude and phase errors straight away.
As always though, experiment !!
- If the source you are trying to self-calibrate is polarized, but
you have loaded the data as polarizations rather than converting to
Stokes parameters, then recall that XX = I + Q and YY = I - Q, so
that you must average XX (called RR) and YY (called LL) before
trying to work out a self-calibration solution. Do this by setting
doavg=1. If the source is unpolarized, it may still be advantageous
to do this, as it will boost your signal-to-noise ratio slightly. If
you have converted to Stokes parameters, then set doavg=-1.
|
ATMCAL |
| inname,inclass,inseq,indisk | Select data base |
|
sources='0412-23' | Select source |
|
qual=-1 | Select all qualifiers or specify |
|
freqid=2 | One run per freqid |
|
docalib=1 | Calibrate data with |
|
gainuse=2 | the correct CL table |
|
flagver=0 | Select flagging table |
|
in2name,in2class,in2seq,in2disk | Select CLEAN image for model |
|
invers=0 | Select CLEAN component file version |
|
ncomp=250 | Select number of CLEAN components |
|
| to use for the model |
|
smodel=1.3,-34.2,54.3 | Use point source model rather |
|
| than CLEAN components |
|
uvrange=0 | Specify uv range to match model |
|
wtuv=0 | Zero weight for points |
|
| outside of uv range |
|
refant=3 | Specify the reference antenna |
|
solint=1 | Solution time in minutes. |
|
soltyp=' ' | Least squares algorithm. If too many |
|
| failed solutions, try 'L1' |
|
solmode='a&p' | Solve for amplitude and phase |
|
doavg=1 | Average XX and YY together |
- After the new solutions have been generated, examine them, as
always, with SNPLT. Once you are happy with the results, apply them to
the current CL table and write a new CL table; remember, CL tables are
cumulative.
|
ATCLCAL |
| inname,inclass,inseq,indisk | Select input data base |
|
sources='0412-23',' ' | Select source |
|
calsour='0412-23' | |
|
calcode=' ' | Leave blank |
|
freqid=1 | One freqid per run |
|
timerang=0 | Select time range |
|
interpol='2pt' | Select two point interpolation |
|
gainver=2 | Apply solutions to current CL table |
|
gainuse=3 | and update to next CL table |
|
refant=3 | Select ref. antenna |
- If you are using single-source files, then use the procedure
ATSCAL which has inputs very similar to ATMCAL. I refer you to the
discussion above for details. The main differences are the inclusion of
the output corrected data base adverbs outname, outclass,
outseq, and outdisk, and the absence of flagver,
gainuse and the need to run CLCAL. Note that an SN table is still
generated so that you can inspect the solutions. It is attached to the
input data base.
|
ATSCAL |
| inname,inclass,inseq,indisk | Select data base |
|
sources='0412-23' | Select source |
|
qual=-1 | Select all qualifiers or specify |
|
freqid=2 | One run per freqid |
|
docalib=1 | Calibrate data with |
|
gainuse=2 | the correct CL table |
|
flagver=0 | Select flagging table |
|
in2name,in2class,in2seq,in2disk | Select CLEAN image for model |
|
invers=0 | Select CLEAN component file version |
|
ncomp=250 | Select number of CLEAN components |
|
| to use for the model |
|
smodel=1.3,-34.2,54.3 | Use point source model rather |
|
| than CLEAN components |
|
outname,outclass,outseq,outdisk | Specify output corrected data base |
|
uvrange=0 | Specify uv range to match model |
|
wtuv=0 | Zero weight for points |
|
| outside of uv range |
|
refant=3 | Specify the reference antenna |
|
solint=1 | Solution time in minutes. |
|
soltyp=' ' | Least squares algorithm. If too many |
|
| failed solutions, try 'L1' |
|
solmode='a&p' | Solve for amplitude and phase |
|
doavg=1 | Average XX and YY together |
- You might also consider the task KALIB. This is a clone of
CALIB, but it allows you to specify a uvrange (via the different
adverb uvlimit for each subarray in the file (e.g. if you have
concatenated configurations together with DBCON you will have several
subarrays). With ATCA data, it is often crucial to finely tune the
uvrange (e.g. to exclude just one shortest spacing in each
configuration) and the uvrange adverb applies to all
configurations in the file so that you end up excluding or including spacings
undesirably. See the EXPLAIN file for more details.
- It may occur that you wish to apply an SN table to a
single-source file and write out the corrected visibilities (we apply CL
tables to multi-source files and SN tables to single-source files). For
example, you may be working on spectral-line data, and there is a strong
maser at one channel. You can use this maser, which is easily
self-calibrated, to generate solutions that you would then like to apply
to say, a continuum data base. You simply copy the SN table to the
desired single-source file, and then apply it with SPLIT (although in
this case there is no `splitting', just application of the SN table) by
setting docalib=1.
Last update : 27/11/93
1
APPENDICES
Next: AVAILABLE TASKS in AIPS
Up: SELF CALIBRATION
Previous: General
nkilleen@atnf.csiro.au